Introduction
The goal of this notebook is to characterize the dataset and ultimately help predict medical charges based on factors like age, sex, bmi, number of children, smoking status, and region of living.
Let us start with loading the necessary packages for this analysis.
Show me the code
<- c ("shiny" , "tidyverse" , "lubridate" , "randomForest" , "plotly" ,"ggstatsplot" , "corrplot" , "Hmisc" , "flextable" , "DT" , "networkD3" ,"ggrepel" , "leaflet" , "maps" , "ggforce" , "lmtest" , "ggpubr" )<- packages %in% rownames (installed.packages ())if (any (installed_packages == FALSE )) {install.packages (packages[! installed_packages])invisible (lapply (packages, library, character.only = TRUE ))library (shiny)library (tidyverse)library (lubridate) library (randomForest)library (plotly)library (ggstatsplot)library (corrplot)library (Hmisc)library (flextable)library (DT)library (networkD3)library (ggrepel)library (leaflet)library (maps)library (ggforce)library (lmtest)library (ggpubr)<- theme_bw () + theme (plot.title = element_text (size= 20 ),axis.title = element_text (size = 15 ),axis.text = element_text (size = 12 ),legend.title = element_text (size= 12 ),legend.text = element_text (size= 12 ))
Data Upload and Clean-up
Show me the code
<- read.csv ("medical_cost.csv" )<- medicalcost %>% mutate (BMI.status = case_when (< 18.5 ~ "Underweight" ,>= 18.5 & bmi < 24.9 ~ "Normal" ,>= 25 & bmi < 29.9 ~ "Overweight" ,>= 30 ~ "Obese" ,TRUE ~ "Unknown" )) %>% mutate (BMI.status = factor (BMI.status, ordered = TRUE ,levels = c ("Underweight" , "Normal" , "Overweight" , "Obese" , "Unknown" ))) %>% mutate (children = factor (children, ordered = TRUE ,levels = c ("0" , "1" , "2" , "3" , "4" , "5" ))) %>% mutate (sex = factor (sex, ordered = TRUE , levels = c ("male" , "female" ))) %>% mutate (smoker = factor (smoker, ordered = TRUE , levels = c ("no" , "yes" ))) %>% mutate (region = factor (region, ordered = TRUE , levels = c ("northeast" , "northwest" , "southeast" , "southwest" )))
I added a variable to stratify the BMI into 4 different categories: Underweight, Normal, Overweight, and Obese. I also transformed the sex, bmi status, children, smoking status, region into categorical factors. The resulting data frame is as follows:
Show me the code
<- medicalcost %>% datatable (filter = list (position = "top" , clear = FALSE ),options = list (columnDefs = list (list (className = "dt_center" , targets = "_all" )),scrollX = TRUE ),caption = "Medical cost dataset"
Exploratory Data Analysis
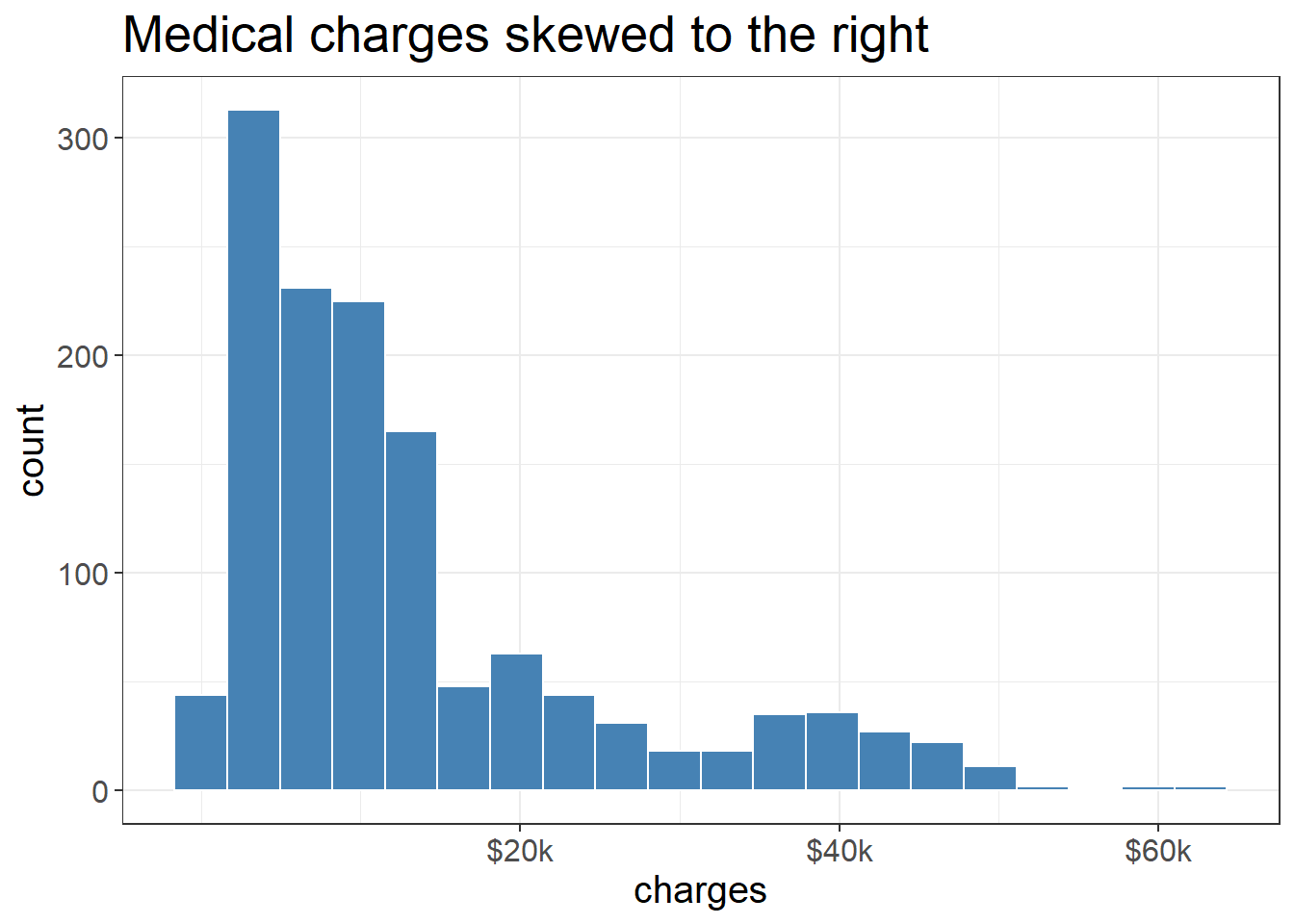
Distribution of medical charges in the data set
Show me the code
ggplot (medicalcost, aes (x = charges)) + geom_histogram (bins = 20 , fill = "steelblue" , color = "white" ) + labs (title = "Medical charges skewed to the right" ) + scale_x_continuous (breaks = c (20000 , 40000 , 60000 ),labels = c ("$20k" , "$40k" , "$60k" )) +
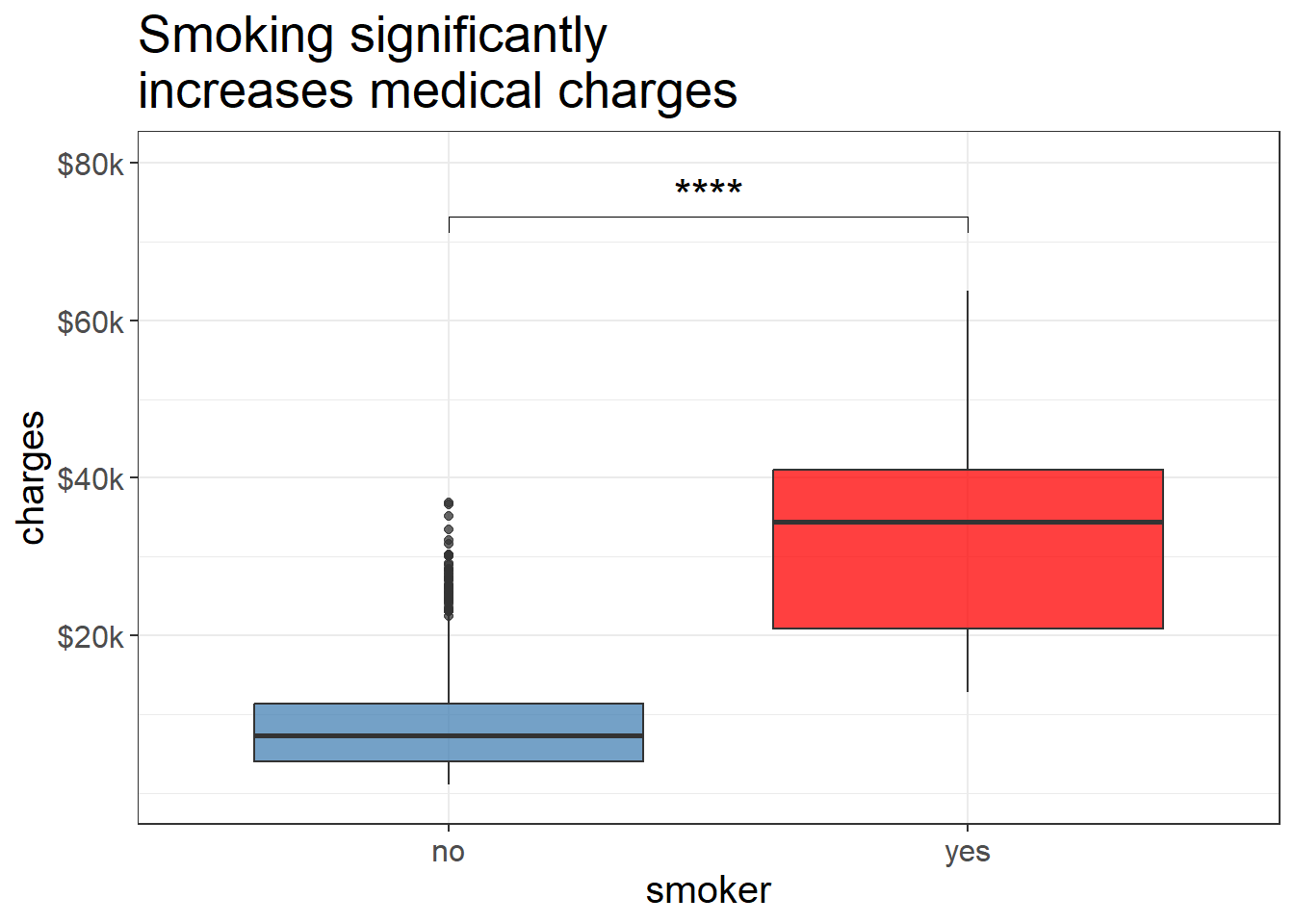
Smokers have higher medical cost than non-smokers
Show me the code
<- list (c ("yes" , "no" ))ggplot (data = medicalcost, aes (x = smoker, y = charges, fill = smoker)) + geom_boxplot (alpha = 0.75 ) + labs (title = "Smoking significantly \n increases medical charges" ) + scale_fill_manual (values = c ("yes" = "red" , "no" = "steelblue" )) + stat_compare_means (comparisons = smoking.comparison, aes (label = ..p.signif..), label.y = 70000 , size = 6 ) + + theme (legend.position = "none" ) + scale_y_continuous (limit = c (0 , 80000 ),breaks = c (20000 , 40000 , 60000 , 80000 ),labels = c ("$20k" , "$40k" , "$60k" , "$80k" ))
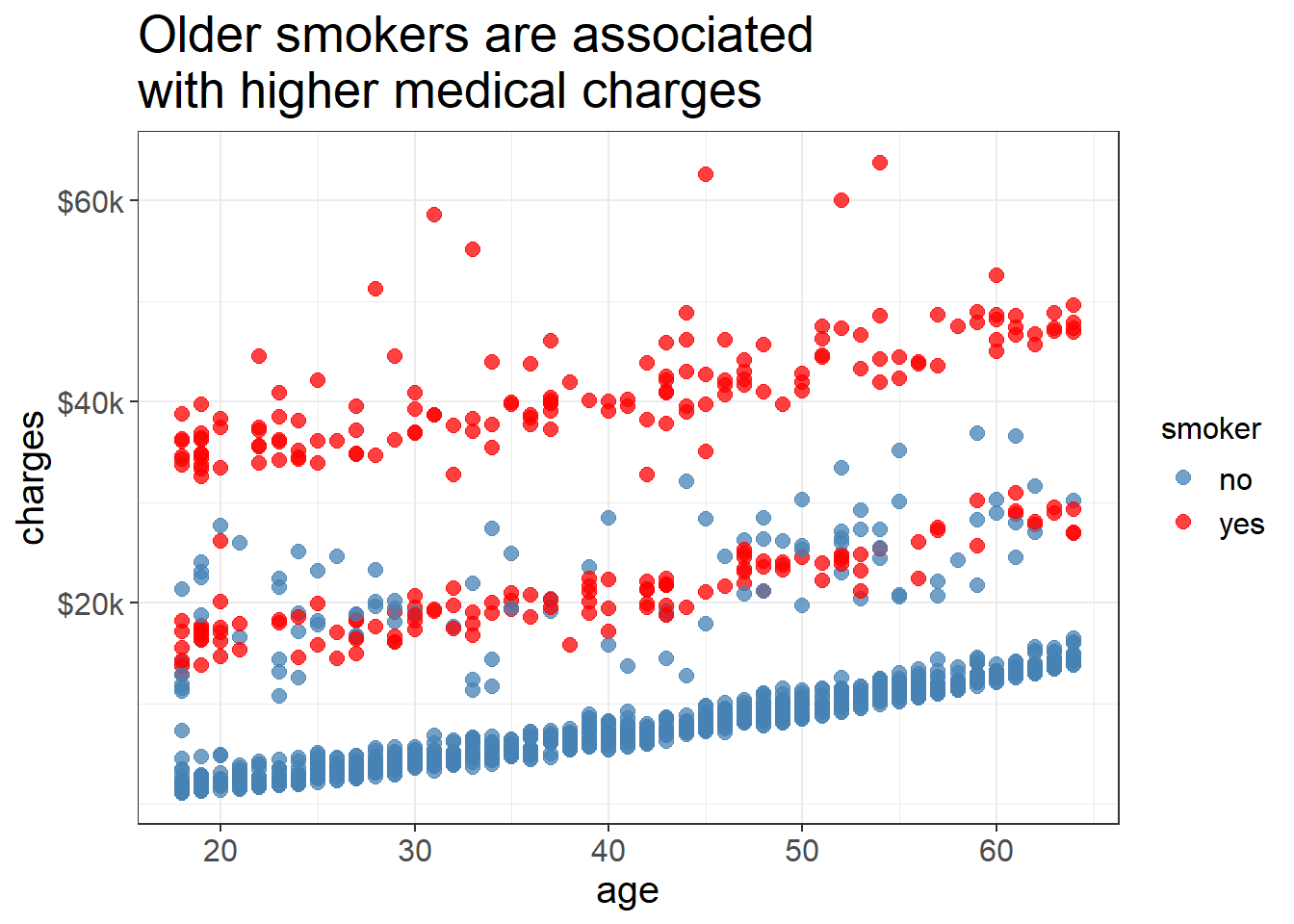
Unpaired T test suggests that smokers have higher cost of medical charges than non-smokers. How does these two groups affect the medical cost with a third variable, such as age and BMI?
Relationship between age and medical cost
Show me the code
ggplot (medicalcost, aes (x = age, y = charges, color = smoker)) + geom_point (alpha = 0.75 , size = 2.5 ) + scale_color_manual (values = c ("yes" = "red" , "no" = "steelblue" )) + labs (title = "Older smokers are associated \n with higher medical charges" ) + scale_y_continuous (breaks = c (20000 , 40000 , 60000 ),labels = c ("$20k" , "$40k" , "$60k" )) +
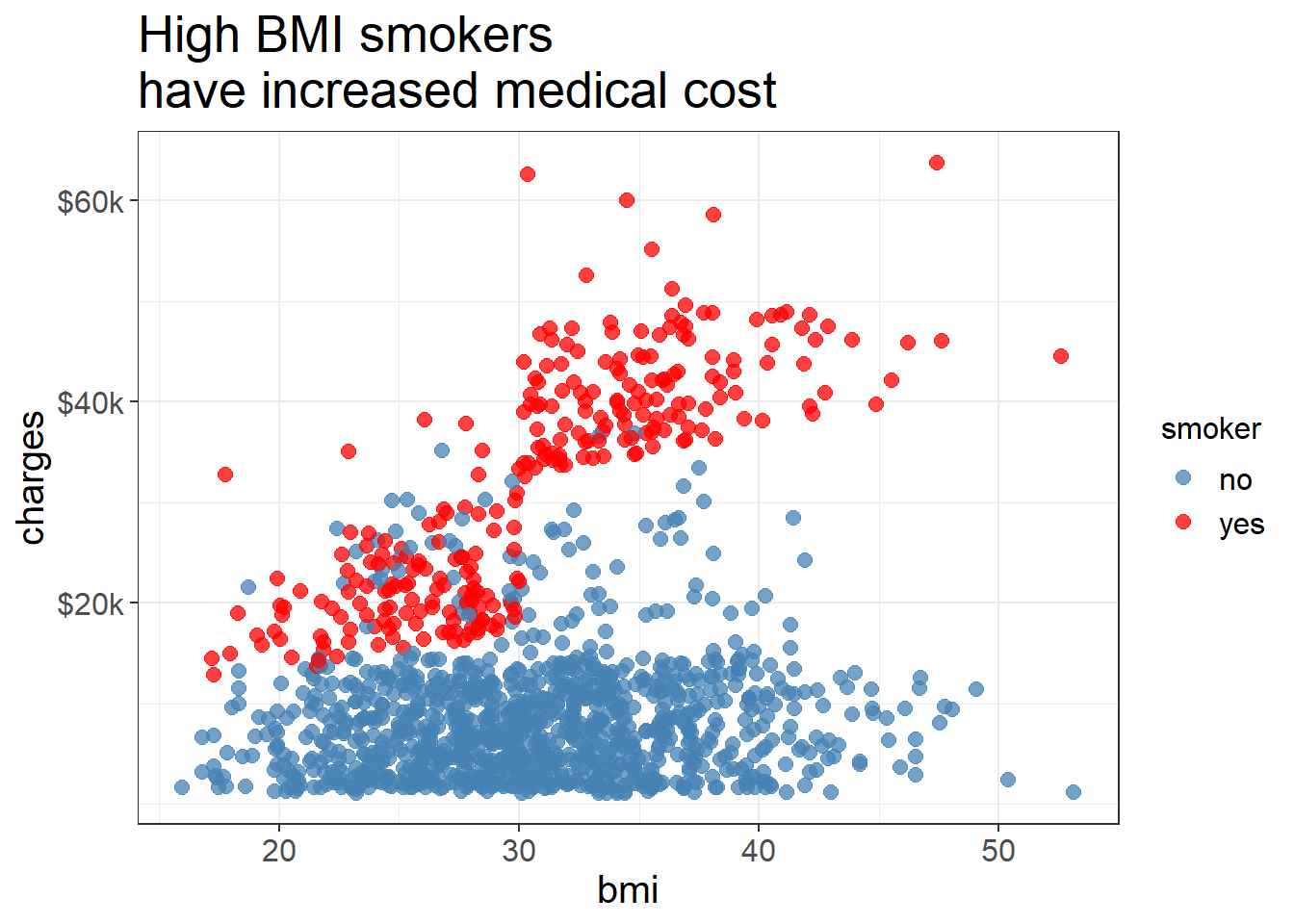
Relationship between BMI and medical cost
Show me the code
ggplot (medicalcost, aes (x = bmi, y = charges, color = smoker)) + geom_point (alpha = 0.75 , size = 2.5 ) + scale_color_manual (values = c ("yes" = "red" , "no" = "steelblue" )) + labs (title = "High BMI smokers \n have increased medical cost" ) + scale_y_continuous (breaks = c (20000 , 40000 , 60000 ),labels = c ("$20k" , "$40k" , "$60k" )) +
Model using Multiple Linear Regression
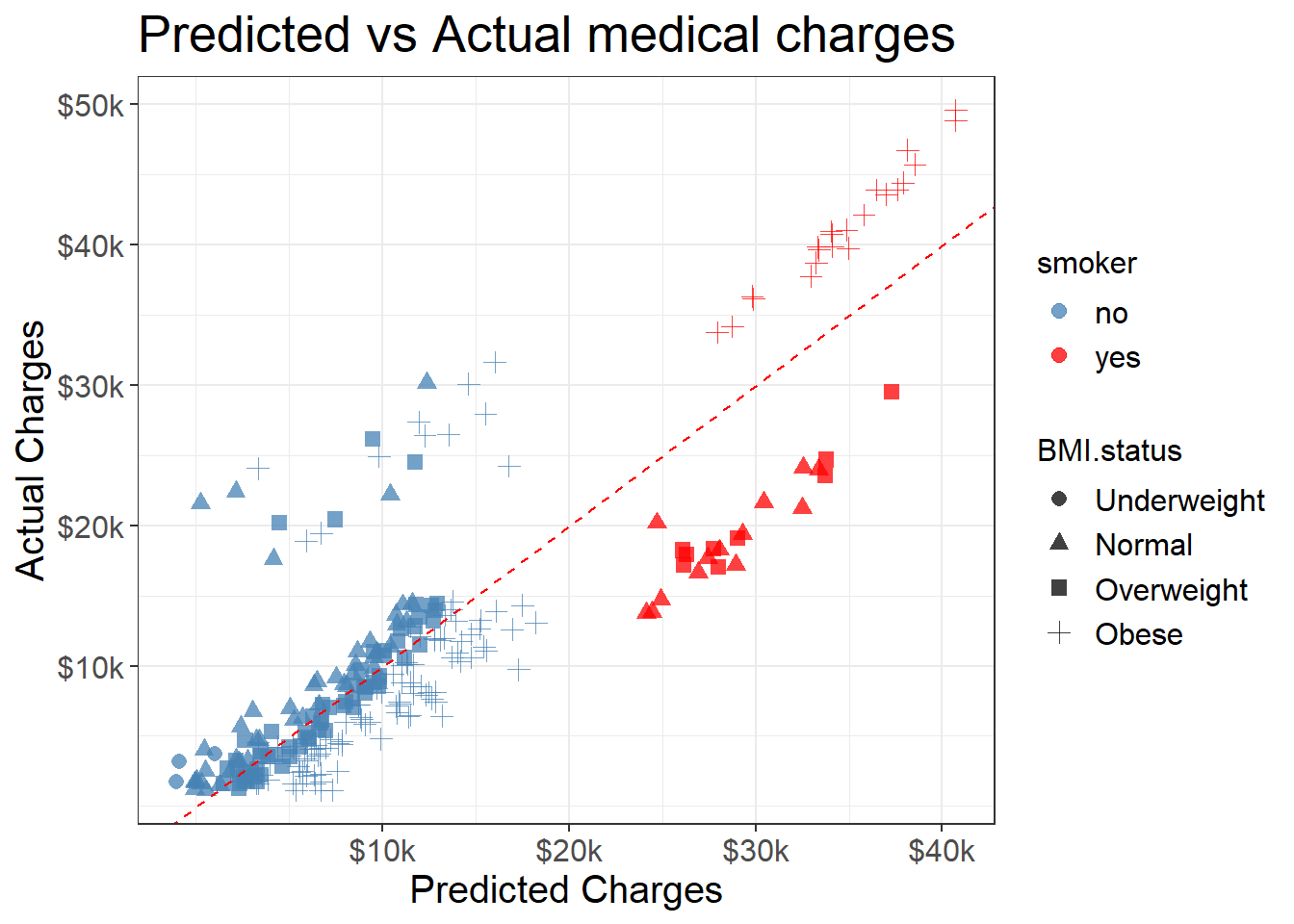
Test the model using 20% of the data
Show me the code
$ predicted <- predict (model, newdata = test_data)<- test_data %>% filter (BMI.status != "Unknown" )ggplot (test_data, aes (x = predicted, y = charges, color = smoker, shape = BMI.status)) + geom_point (alpha = 0.75 , size = 2.5 ) + scale_color_manual (values = c ("yes" = "red" , "no" = "steelblue" )) + geom_abline (slope = 1 , intercept = 0 , color= "red" , linetype= "dashed" ) + labs (title = "Predicted vs Actual medical charges" ,x = "Predicted Charges" , y = "Actual Charges" ) + scale_y_continuous (breaks = c (10000 , 20000 , 30000 , 40000 , 50000 ),labels = c ("$10k" , "$20k" , "$30k" , "$40k" , "$50k" )) + scale_x_continuous (breaks = c (10000 , 20000 , 30000 , 40000 ),labels = c ("$10k" , "$20k" , "$30k" , "$40k" )) +
In our model testing, we see that the model underestimates actual medical charges for smoking obese demographic.